

Over a year ago I wrote about bold migrations and how our platform team had flipped the script: instead of asking product teams to slowly grind through upgrades, we took the lead, planned backwards from clear end‑states, and did most of the work for them.
Since then, coding agents have matured as we were standardising how we migrate. The timing turned out to be very lucky: the same patterns that made human‑led bold migrations possible also made them agent‑friendly. Today, we have migrations where the “human work” is much closer to defining intent and approving changes than hand‑cranking every step.
A year ago, “agents doing bold migrations” would have sounded like marketing. Today, for whole classes of change—infrastructure migrations, data migrations, routine upgrades—it’s a fairly literal description of how the work actually happens.
Our new Bold AI Principles
Although every organisation’s stack and constraints are different, I believe there are a few patterns that have felt broadly applicable.
-
Standardise before you automate. If every team does CI, deployments or data access differently, agents will struggle just as much as humans do. Invest in common patterns first.
-
Write playbooks that a new hire could follow. If a junior engineer could run a migration following a document, an agent probably can too. If they couldn’t, you’re not ready to automate. You either need to reduce the scope of the migration or simplify it.
-
Separate frameworks from implementations. Build reusable cores; keep product‑ or team‑specific logic in skills and adapters. It’s easier to test, easier to document, and easier for agents to work with. (We show this in practice in our technical deep-dive.)
-
Design infrastructure for short‑lived, least‑privilege access. That’s good security practice anyway—and it makes it far easier to reason about what agents can and cannot do.
-
Think of agents as junior teammates, not external contractors. External contractors often work to a rigid spec without internal context or a stake in the long-term outcome. Junior teammates, however, are part of the “whole”—they require onboarding, access to our shared culture (standardization), and consistent mentorship (review). They are great at grinding through standardized work and maintaining consistency across a large surface area, but they rely on you for judgment and accountability. You don’t just give them a ticket; you give them a mission and the context to succeed.
From bold migrations to agentic migrations
When we first started talking about bold migrations, the goal was to turn a perennial pain point into a competitive advantage. A year on, the story is starting to compound: bold migrations are no longer just something platform teams lead—they’re increasingly something our agents can execute, safely and repeatedly, on our behalf.
Our original strategy rested on a few simple ideas:
- Platform does 80% of the work; product teams bring 20% of the context.
- Plan backwards from the end‑state. Start with “this old system is shut down by this date”, then work back into milestones, sequencing and ownership.
- Prove it within your team before you roll it out globally. A “future team” adopts the new thing first and demonstrates real wins; only then do we roll it out as a migration to everyone else.
That approach forced us to create repeatable playbooks instead of one‑off projects. We defined:
- How we choose candidates for migration.
- How we schedule teams across quarters.
- How we handle Day 1 operations and Day 2 hand‑over.
Those same playbooks turned out to be exactly what agents need: clear starting conditions, a well‑defined workflow, and an obvious notion of “done”.
In our 2026 planning, we wrote this down explicitly: the platform organisation should become AI‑first, with agents handling end‑to‑end execution of our most repetitive flows, with humans setting intent and acting as the safety net.
Once you treat migrations as well‑defined workflows, the question almost asks itself:

CI pipelines: the first large‑scale agentic migration
Turning CI migration into a playbook
Our continuous integration (CI) setup had grown organically over years. Different teams used different patterns and slightly different stacks; moving everyone to a modern CI platform was clearly valuable, but painful.
Before we brought agents into the loop, we did something more boring: we wrote down a migration playbook in detail. It covered things like:
- How to analyse an existing pipeline definition and infer:
- What’s being built and tested.
- Which artifacts (images, packages, charts, manifests…) are actually published.
- Which cloud roles, secrets and environments are required.
- How to introduce a new CI workflow in “dry‑run” mode that:
- Runs in parallel with the legacy system.
- Executes all validations.
- Does not publish anything yet.
- How to promote a project to “new CI as the source of truth” once we’re confident:
- Enabling publishing in the new pipeline.
- Disabling the legacy system.
- Cleaning up configuration and files that are no longer needed.
In many companies this knowledge lives in people’s heads or scattered Slack threads. This was the 20% context we needed from the teams, and if we could discover this ourselves, we were able to migrate a large amount of our systems without needing help from the engineering teams.
Letting agents drive the migration
Once our playbook was defined, we turned it into a set of automated agent commands. This shifted the heavy lifting from developers to AI, leaving humans to simply review and approve.

1. The Migration Workflow
The agent handles the “grunt work” across three phases: a Dry Run that prepares the repository and stands up the new pipeline alongside the legacy one, a Pull Request that packages the change with a human-readable summary and validation checklist for review, and a Promotion after a dual-running period. The engineering behind each step is covered in our companion deep-dive, 3 Years to 3 Months.
2. Why Agents?
By standardizing the migration process, we enabled agents to navigate the technical complexity autonomously, handling the operational heavy lifting while humans keep total control, reviewing every change before “pulling the trigger.” (How the agent actually translates legacy logic into the new format is the subject of our technical deep-dive.)
3. Scaling with the Backlog
To handle the scale of the entire organization, we added a Bulk Migration skill, guardrails and resiliency. This allowed us to manage a massive backlog and migrate entire clusters of repositories for teams simultaneously. (the Selective Supervision mechanics are in Part 3)
4. Tracking
We also invested in tracking: simple spreadsheets and dashboards that show, per team and per repository, which phase each project is in (legacy only, dual‑run, fully migrated). That makes it easy for agents to select the next candidates and for humans to understand progress at a glance.
![]()
5. The result
The true catalyst wasn’t just the AI—it was standardization. By enforcing consistent naming conventions and architectural patterns, we created an environment that was equally “readable” for both humans and LLMs.
We avoided the common pitfall of attempting 100% automation, which often leads to brittle systems and business disruption. Instead, we applied the 80/20 rule: delegating the bulk of the repetitive work to AI while reserving high-risk, complex edge cases for manual migration. For example, the blast radius and custom logic of our primary monorepo still demand human architectural judgment. This pragmatic approach ensured both velocity and safety.
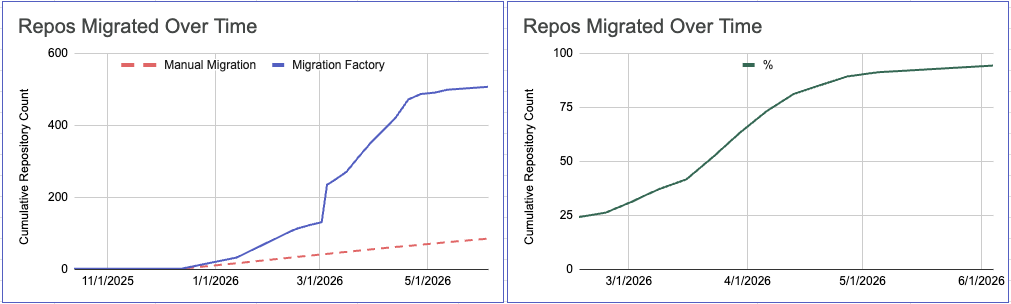
The results of this “AI Factory” were transformative. In just one quarter, a small team of engineers successfully migrated over 500 repositories to an entirely new CI/CD stack. A project of this magnitude would typically require a year-long for a team of 3-4 engineers, massive coordinated effort involving dedicated migration squads embedded in every department. Instead, we reduced the bottleneck of manual labor to a monitoring task, with humans acting as the final layer of review.
What should you take away from this
The shift from human-led to agent-augmented migrations has fundamentally rewritten our internal economics. When we look at the effort required to move 400+ repositories, the breakdown has evolved into something transformative:
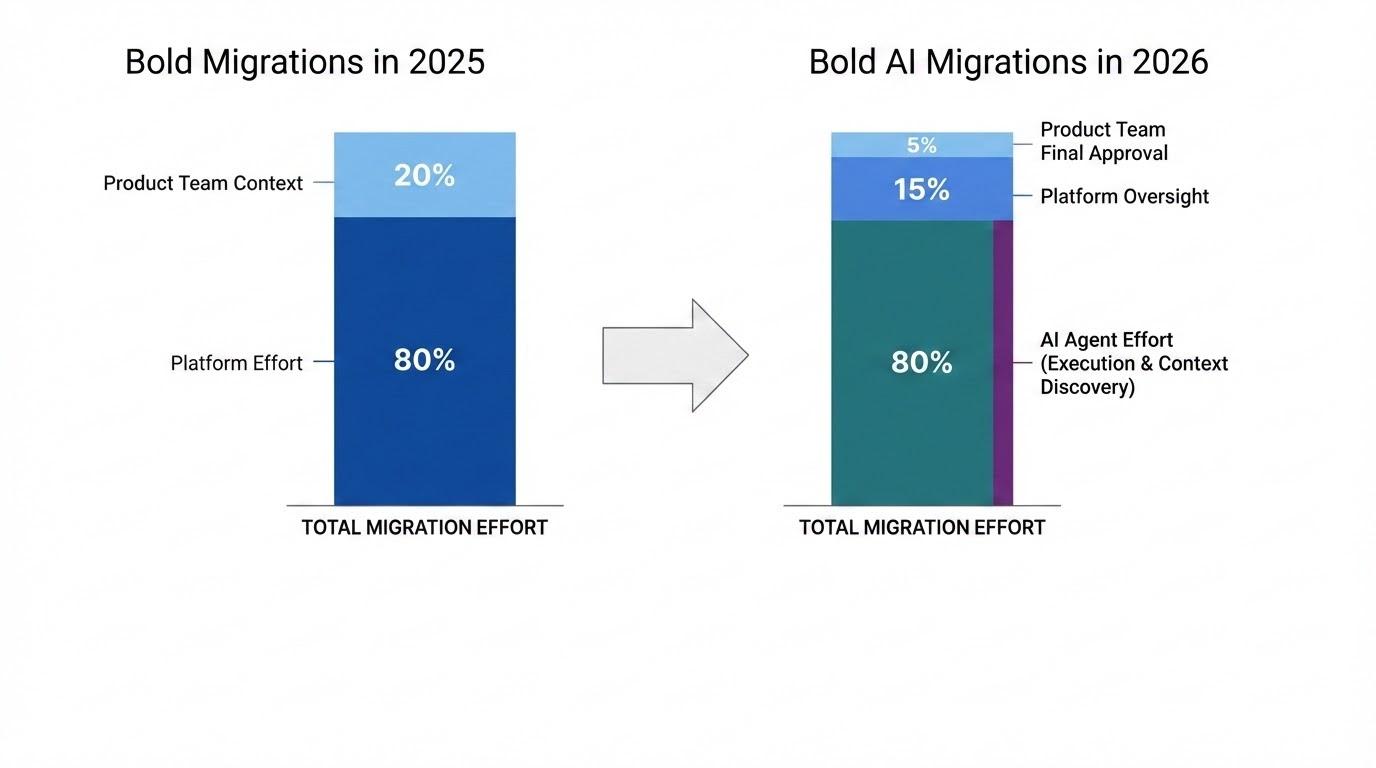
The Platform Effort (80%): What used to be a massive manual lift for our team is now 65% Agent execution and 15% Platform oversight.
The Engineering Context (20%): Because our playbooks allow agents to discover the necessary context (secrets, roles, and dependencies) autonomously, the product team’s involvement has shrunk to 15% Agent discovery and a mere 5% human final approval.
But that is not the most significant win—it’s the silence. I can feel migrations changing from an Organizational Tax to Background Task.
In the old model, a migration of this scale would have required months of “noisy” cross-team planning, endless Jira tickets, disruptive status updates and escalations to directors and VPs. By shifting 80% of the total CI migration effort to agents, we have turned a major organizational hurdle into a background process.
We’ve effectively decoupled infrastructure evolution from developer cognitive load. Our 2026 reality is one where the platform can stay modern, secure, and performant without asking the rest of the company to stop building. We provide the intent; the agents provide the momentum.


