

This is Part 3 of a 3-part series on how we used GenAI to speed up a full-scale CI migration.
Part 1 — Going Fully Local
Part 2 — A Multi-Step Agentic Analysis Chain
Part 3 — Deterministic at Edges (you are here)
TL;DR
We developed a GenAI Migration Framework based on a repeatable design that sped up a full-scale CI migration 13 times over.
Intrigued by the engineering behind the magic? This part focuses on what guardrails we employed to maintain high accuracy, and how we ran surgical fixes over hallucinated output. We also show how the agentic approach has truly sped up our process
In the previous chapters we covered why we ran the flow fully local (Part 1) and how we split it into a four-phase agentic chain (Part 2). Here, we tackle the final challenge: keeping all that speed without sacrificing accuracy.
Problem #3 — The Need for Speed vs The Fragility of complex migrations
Agentic workflows deliver work at superhuman speed, but their outputs are non-deterministic and of variable quality. This is a serious risk in brownfield migrations, where repositories are tribal-knowledge-heavy and a small change can ripple across the stack. (For why we accept that trade-off and what it changes organizationally, see Bold AI Migrations: One Year On.) Here, we focus on the engineering aspect of this tradeoff: How do we keep a high development speed, without sacrificing accuracy
How did we solve it? Deterministic at Edges, Unburdened at Core
In designing our automation, we followed two main principles to ensure we strike a balance between accuracy and delivery speed:
- Keeping humans in the loop using Selective Supervision.
- Designing our LLM-heavy flows to be “Deterministic at Edges” — strict, schema-defined boundaries around an exploratory core.
Both principles serve different purposes, but both contribute to the same goal of helping the workflow strike a proper balance between determinism and agility.
First, to clarify the term - by “Deterministic at Edges”, we mean enforcing a practice where the I/O channels of the LLM’s agent session are bound to be JSON-only, and are actively schema-enforced using static JSON analysis scripts. At the same time, apart from providing detailed prompts and checkpoints - We don’t guardrail the inner workings of the session at all, letting the LLM explore and do what it does best.
Selective Supervision — control gates where oversight matters
We employed Selective Supervision, first of all, by choosing to keep the automation flow fully local. For a transient migration tool - developed at a time when “GenAI Infrastructure” was still a blooming concept - running the tool locally gives us the ability to choose when to loosen the reins in the flow versus where we want to closely verify each step. We allowed the automations to reach varying speeds by gating different segments of the automation with control gates. Some of these were rigid and human-supervised, such as approving the implementation plan post-analysis; others were “softer” and signified a point in the flow where the agent should pause and verify it is still on track, such as verifying all objectives have been reached before pushing changes.
Additionally, some of the Selective Supervision is implemented by presenting the user with choices regarding the preferred implementation approach. One feature the skill supports is the parallel analysis and implementation of multiple candidate repositories at the same time. If some analysis cases signal a more complex migration requiring custom adaptations, the overseeing engineer can choose to “split” the batch - implementing the simpler repositories automatically and then circling back to implement changes in the complex repositories in a more interactive session with higher human involvement.
Guardrails around the core
Another aspect in which we imposed smart guardrails was around the core of the process: the LLM-heavy analysis flow. We wanted to allow the LLM to leverage its autonomy and analytical capabilities - which are the main factors driving it apart from static automations - but we also wanted to safeguard against hallucinations and ensure the results remain in line with our expectations. To achieve this, we employed our “Deterministic at Edges” approach; meaning, we enveloped the four agentic phases with a strict, schema-enforced interface. As mentioned earlier, the different phases communicate using schema-enforced JSON documents; however, providing the interface would be meaningless without verifying its use. We could define the interface and still receive malformed JSONs with missing fields or non-compliant data.
The solution we devised was a hybrid approach. As a reminder, the analysis flow performs four calls to the different agentic phases from a shell script - a fact we relied on heavily for our guardrailing solution. While the phases themselves ran rather unobstructed, provided only with the schema data and guidelines for the expected output, the moment they produced their JSON documents, the output files were piped into formalized jq queries hardcoded into the bash script. These were designed to ensure the output files completely followed the expected schema.
The Fixer: repairing invalid output
If gaps are found - such as a hallucinated field name or empty fields - instead of dropping the output or forcing a retry, we call a dedicated agent prompt: the “Fixer.” The agentic Fixer component came into fruition once we saw that Determinism at Edges can also create some issues - As LLMs are indeterministic in nature, it’s difficult for them to comply into a predefined schema 100% of the time - Especially when we’re talking about a migration project covering hundreds of repos, where we’ll be sure to find some repos “slightly bending the rules” and confusing the LLM. As a result, we saw that sometimes - some of the JSON outputs result in empty / half empty. Those corruptions seeped through the workflow, eventually causing an overtly generic / truncated final analysis.
Our initial, naive approach - Simply retrying the whole phase again, then even retrying the entire analysis workflow - Failed too, as inconsistencies just popped up elsewhere, and the overall execution time was slowly becoming too long to tolerate. We realized we needed a more focused, surgical solution. Enter “Fixer”.
How the Fixer works
The Fixer’s sole purpose is to take the missing schema fields and “cherry-pick” the relevant bits from the original phase’s prompt and inputs to backfill them. The inputs are rather straightforward - It includes all of the context the original phase had + the corrupted output JSON. Its prompt is very focused - Here’s the failed phase and its prompt. Here’s the corrupted result and source data. Fill only the corrupted pieces, without attempting to rec-reate the whole output again. The Fixer is allowed two retries: the first with a cheaper model (from the Haiku family, in our case), and the second with a more expensive one (from the Sonnet family, in our case). If neither retry fixes the output, it is forwarded as-is; we would rather have a partially complete analysis than none at all.
To our surprise, the Fixer’s contribution was beyond what was expected - At the first three weeks of execution, over which we analysed the specific Fixer metrics - 100% of corruptions were correctly handled using the Haiku-powered fixer. The prompt and missions were so directed, we didn’t even need to employ a stronger model for the fix - Which drastically improved the general accuracy of the analysis’ results.
Attached below is a diagram of that verification process, exemplified on the Extract-to-Draft interface of the workflow, which is identical for all internal interfaces.

How did it turn out?
While the development process of this agentic workflow required several iterations to reach its current state (a process that took only about 1.5 weeks of engineering hours to complete), the results speak for themselves. The chart below shows the projected manual migration rate (in red) versus the actual migration rate we achieved (in blue), highlighting the points where development of the migration workflow started and where it was released internally for all team members to use.
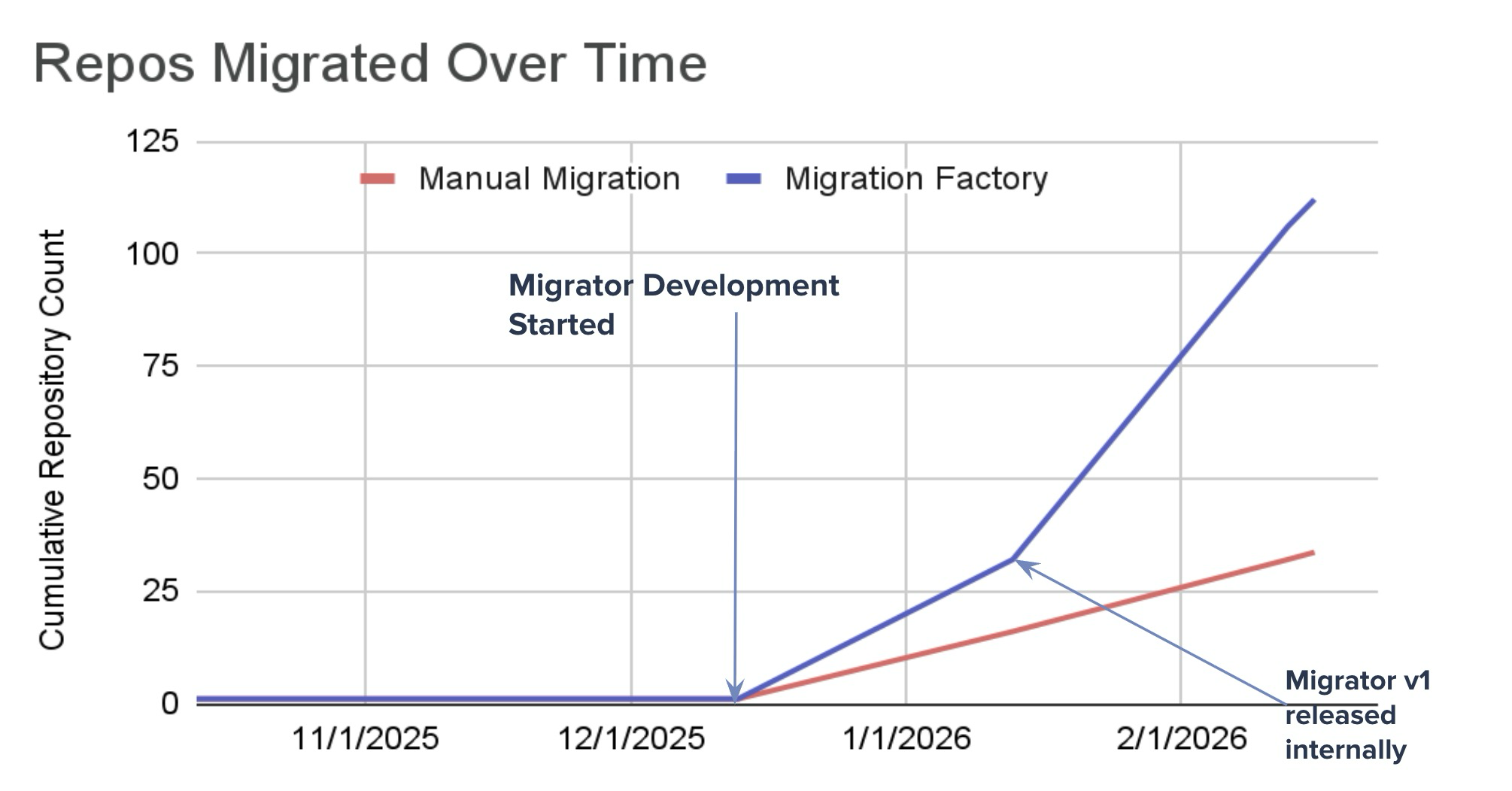
This chart, showcasing the development month and first month “out in production” for the workflow, showcase really well the increase we noticed - Whereas the red trendline shows the manual migration pace we were to expect if we started migrating the same day we started development of the Migrator - The blue trendline, showcasing our actual migration cadence - Shoots up.
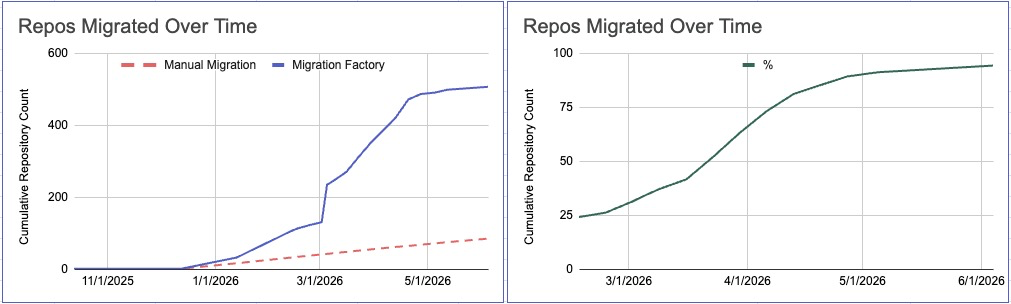
The same can be seen by looking at those graphs, showcasing the entire project’s acceleration (the green trendline measures percentage of repos migrated, starting at when we started measuring it). As mentioned at the first article - We can see that the trendline starts to plateau around the 91% mark - Which leaves just the highly custom workflows for us to resolve. Those workflows were never intended to be migrated using the migrator - And we’re still able to use several insights from running the migration on them to “shake off some of the dust”, and help the engineer working on the migration gets contextualized faster
The massive success of this workflow in this migration project helped emphasize the significant impact that intentionally-engineered agentic workflows can have on messy brownfield platform migrations, potentially helping us launch Forter’s internal platform ecosystem forward with a fraction of the estimated effort.
Future Plans
Regarding future improvements for our next agentic workflow attempts,
As the GenAI stack keeps evolving, we now have access to capabilities we didn’t have when we started, such as hosted agentic execution engines. These could offload the heavier “technical” work (analysis and implementation) from local hardware to stronger, asynchronous cloud infrastructure, while keeping the same Human-in-the-Loop feedback model we relied on locally.
Applying the same Agentic Brownfield Migration Framework to other platform migrations across Forter is covered from the strategy side in Bold AI Migrations: One Year On.
Stay tuned for more!


