

This is Part 1 of a 3-part series on how we used GenAI to speed up a full-scale CI migration.
Part 1 — Going Fully Local (you are here)
Part 2 — A Multi-Step Agentic Analysis Chain
Part 3 — Deterministic at Edges
TL;DR
We developed a GenAI Migration Framework based on a repeatable design that sped up a full-scale CI migration 13 times over.
Intrigued by the engineering behind the magic? We’ve put together a comprehensive deep dive into the mechanics of the migration. This part focuses on why we chose a fully local execution setup for the migration workflow.
Let’s start with some background
About a year ago, we were presented with a large task: migrating our CI platform from a custom, legacy Jenkins server to a lean, efficient, and modular GitHub Actions Reusable workflow.
After building a viable draft of the new platform and running it through sufficient testing to start delivering it across the organization, a new problem emerged:
Manually migrating a repository turned out to be a lot harder than we thought, mainly because we had to “extract ancient context” from it. This challenge is typical in brownfield migrations, which are often complex and depend on tribal knowledge extraction. For example, we had to migrate a repo that was very seldom used, was not owned by our team, and had some custom flags and parameters added to its CI process.
We had 500 repos, which maps into 3.4 engineering years of work - and based on the “Bold Migration” philosophy we follow in Forter, all of them were on us to migrate. This was far more time than we could afford to spend on this operation. Luckily, this happened around October 2025, meaning we were right on time to leverage quality jumps in the new models of that time that made such migrations possible.
Results and acceleration
Our solution was an AI-powered Migration workflow, analysing candidate repos to draft the new version of the CI. And the results and acceleration this has provided us with were phenomenal -
From the point the workflow reached its stable state, just under three months passed until we smashed our benchmark. Approximately 90% of our repositories - Which are 100% of our non-custom repos and a bit over that - were migrated to the new platform, with the remaining few being a handful of highly complex, sensitive repos that were manually migrated alongside the main endeavor driven by the agentic workflow - And were never part of the migrator’s “target audience” as a full automation tool. In fact, the migrator’s performance in providing the initial analysis on those has exceeded our expectations - To a point we’ve been using the analysis tool to help with the “tribal knowledge excavation” in those repos. While it’s not as accurate as in the simpler, intended cases - It helps brush of some of the initial dust, and help the engineer working on the migration gets contextualized faster
If we’re measuring this in Engineering hours - migrating all non-custom repos took us ~10 weeks overall, with no more than 3 engineers working on it at every single time - None of them spending the full spring on migrations.
Cutting the projected timeline
Moreso, This use of the CI Migrator allowed our team to drastically cut the migration estimate, calendar-wise. From a projected estimate of roughly a year requiring intensive work from multiple team members, we managed to fully migrate ~91% of all repositories, including 100% of our goal repos, in just under three months. Furthermore, the average burden of migration work on the team was significantly smaller, as reflected by the decreased share of sprint work dedicated to it, all while achieving an incredibly high progression pace. You could read more on how this project has shaped our broader migration philosophies in Bold AI Migrations: One Year On.
But how did we do it?
As expected with a difficult migration, engineering the solution introduced its own set of challenges. Throughout this series of articles, we’ll explore those main hurdles we faced during the development of the migration agent - and the methods we used to solve them.
| Part | Problem | Solution |
|---|---|---|
| 1 | Cloud Agents Lack Context | Fully Local Agentic Flows |
| 2 | Models get “Prompt Overloads” | Multi-Step Agentic Workflow |
| 3 | Stability vs Agility | Deterministic at Edges, Unburdened at the core |
Problem #1: Cloud Agents Lack Context
Our initial attempt was modest: we developed a simple bash script to generate GitHub Issues for candidate repositories. These were then picked up by Copilot’s cloud-based agents to be implemented directly in the source code. However, this approach fell short of our expectations. The Copilot agent lacked cross-repo context, making it difficult to grasp the current state of our CI and supporting platforms, such as our IaC framework. Additionally, performance was too inconsistent for the precision we required; we couldn’t even reliably count on the agent to link the migration task in Asana, our tracking tool.

Our first remediation was to provide Copilot with a more robust prompt. Instead of a templated prompt from a bash script, we created a Claude Code skill (differentiated as a “command” at the time). This skill used the base structure of our root Jenkinsfile (The base manifest file used for describing your CI pipeline in Jenkins) and detailed migration paths for each artifact type - specifically how to structure the new GHA workflow and artifact list based on a repo’s existing Jenkinsfile - to generate a significantly more accurate prompt for Copilot.
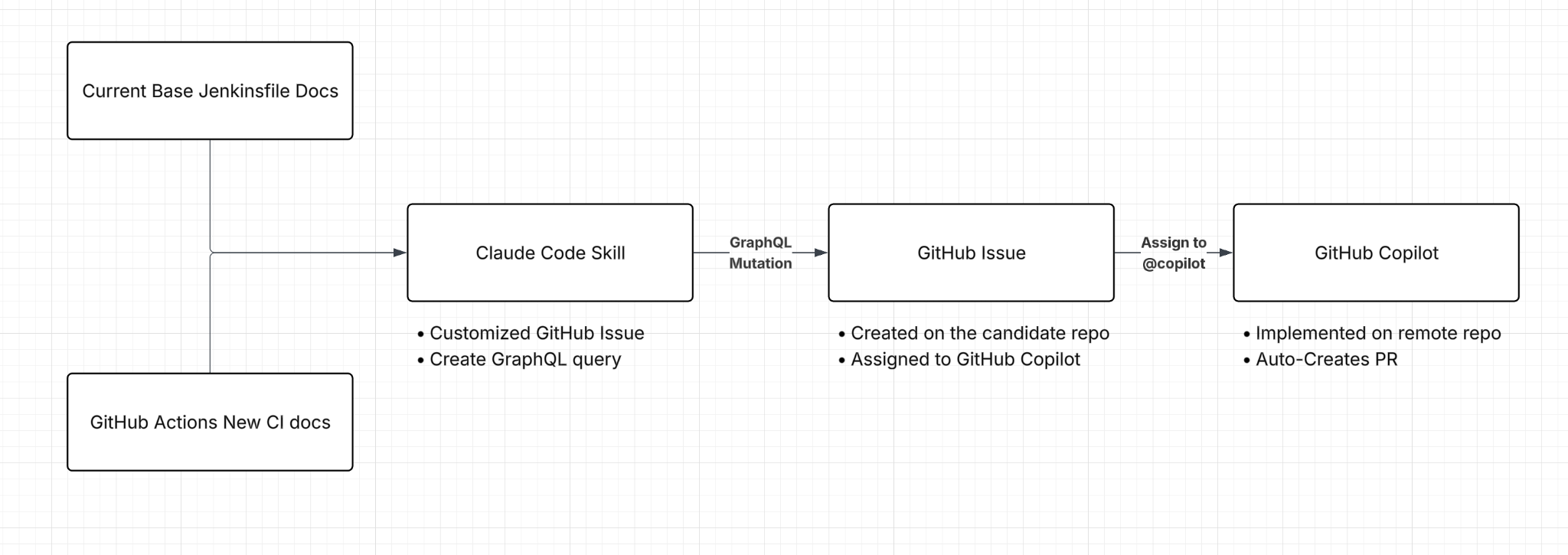
How did we solve it? Going Fully Local
While we initially assumed this adjustment would suffice, we soon learned that the core issue wasn’t just prompt accuracy, but rather the “handoff of the baton” mid-workflow.
Copilot was ultimately working on the migration with only a fraction of the necessary local context. It lacked access to the contextual documentation we provided to the local skill regarding the old and new CI systems, as well as the conclusions the skill had already reached. It only had a finite description, which it took at face value, and information from the candidate repo itself. We noticed that Copilot frequently ignored explicit code snippets intended for the final PR, making errors it never would have committed if it possessed the original local context.
This realization was reinforced when we improved our analysis mechanism, evolving from a single-document skill to a library-like skill featuring a four-phase analysis agent workflow (detailed in the next part).
Where the cloud handoff fell short
While this new approach produced near-perfect analysis of candidate repositories, many of these gains were lost when translated into a Copilot issue description, as the cloud agent often overlooked critical conclusions derived from the source material.
Another point of friction in the cloud-based approach was the necessity of working across multiple repositories for a single migration.
In this refined model, instead of generating a limited GitHub issue for Copilot, the same Claude skill that analyzed the repository handles the implementation itself.
After analyzing the repository and generating a draft, the agent presents a summary of the proposed changes for review:
- A detailed list of CI artifacts detected within the repository.
- Proposed patches for current CI methodologies to eliminate legacy technical debt.
- Specific adaptations required for this repository that deviate from our general CI workflow.
Upon user approval, the agent implements the changes. It creates a temporary, shallow clone of the candidate repository, applies the modifications, and - once verified by the developer - pushes a generated PR directly to GitHub. This allows the workflow to be evaluated live in its dry-run phase against actual infrastructure.
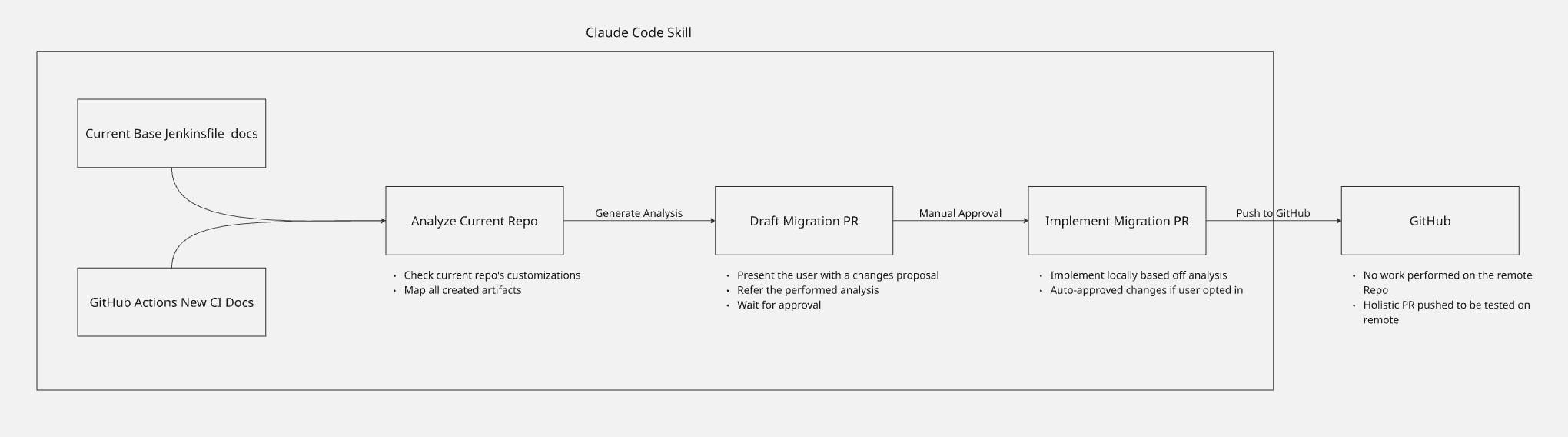
This local-first approach ensured maximum accuracy during implementation while providing the necessary oversight and guidance for the migration effort (more on that in Part 3).
So while the local-first approach indeed drastically improved the amount of context we retained between exploration and implementation - This flow is still a sizable migration effort, and the results we got weren’t consistent enough quite yet. In the next part, we’ll discuss the “Prompt Overloading Issue” we encountered, and how we split the prompt to achieve a satisfactory result.


