

This is Part 2 of a 3-part series on how we used GenAI to speed up a full-scale CI migration.
Part 1 — Going Fully Local
Part 2 — A Multi-Step Agentic Analysis Chain (you are here)
Part 3 — Deterministic at Edges
TL;DR
We developed a GenAI Migration Framework based on a repeatable design that sped up a full-scale CI migration 13 times over.
Intrigued by the engineering behind the magic? This part focuses on how we designed a repeatable format for brownfield platform analysis, and employed it on the CI migration.
In Part 1 we covered why we moved the entire migration flow to run fully local. Here, we tackle the next hurdle: keeping the model on track once the analysis got complex.
Problem #2 — Models Get “Prompt Overloads”
After fully converting our agentic migration system run locally, we encountered a unique phenomenon, which we dubbed prompt overload. Under this unique limitation which is quite apparent across the entire AI Engineering ecosystem nowadays, the model stops following its provided instructions in an orderly manner - skipping segments and sometimes even hallucinating entire sections. Surprisingly, this occurred even when the input was well below the token limit. The solution we devised was arguably the turning point for the quality of our results, and it was as simple as it was impactful: splitting the analysis task into smaller parts.
Just as common productivity advice suggests splitting large tasks into more manageable ones, doing the same for our AI agent drastically improved its performance. While some might argue that this level of engineering is overkill, we believe it is essential for complex, brownfield migration projects. To ensure high-quality, repeatable output, we needed a more granular approach. Created a “library-like” structure of markdown files and prompts helps with differential prompt injection by the Coding Agent based on instructions in a main prompt file; That way, I could, for example, create in-depth prompt “extension packs” for specific bits of migration processes - Especially ones that would be used commonly but not on every migration instance - Which then would help the agent “Plug & Play” instructions based off this repo’s status. We discuss this part in depth in Part 3.
Too much for one prompt
Back to the problem at hand, then. the task we initially entrusted to the skill may sound simple, but it is more nuanced than it appears: “Based on the current state of this repository’s Jenkinsfile and your knowledge of the desired implementations for each artifact type, construct the GHA-based CI workflow call and related configuration files.” This requires the coding agent to:
- Analyze the repository’s Jenkinsfile to understand its existing structure.
- Correlate these findings with shared Jenkins CI logic and the documentation for the new GHA-based system.
- Generate an accurate list of artifacts using our new platform’s JSON schema
- Determine the specific GHA workflow parameters required for the repository.
- Implement the changes and commit them into a pull request.
To tackle these tasks effectively, the agent needed several distinct skill sets: data extraction, JSON construction based on predefined schemas, and gap analysis. Asking a single LLM thread to perform all these actions in a single prompt was simply too much. Consequently, we split the prompt into a chain of smaller, focused prompts based on the following design:
- The “main LLM thread” executes a shell script
- The shell script executes four consecutive agent sessions (using explicit personas and prompts to steer each phase).
- Each phase is “deterministic at the edges,” outputting schema-compliant JSON that we can statically analyze with tools like
jq. - Subsequent phases receive the JSON outputs of previous stages as inputs, preventing redundant analysis and saving time.
This new form of this automation, dubbed the “CI Migrator” by this stage - Serves as a basis to how we envision Brownfield Platform Migrations looking like in Forter in the upcoming future. But what exactly was under those phases, you ask?
How did we solve it? We Engineered a Multi-Step Agentic Workflow
After some trial and error, we finalized a four-phase composition that we found most effective. We believe this process is highly reproducible for other complex migration cases. The workflow follows a logical progression:
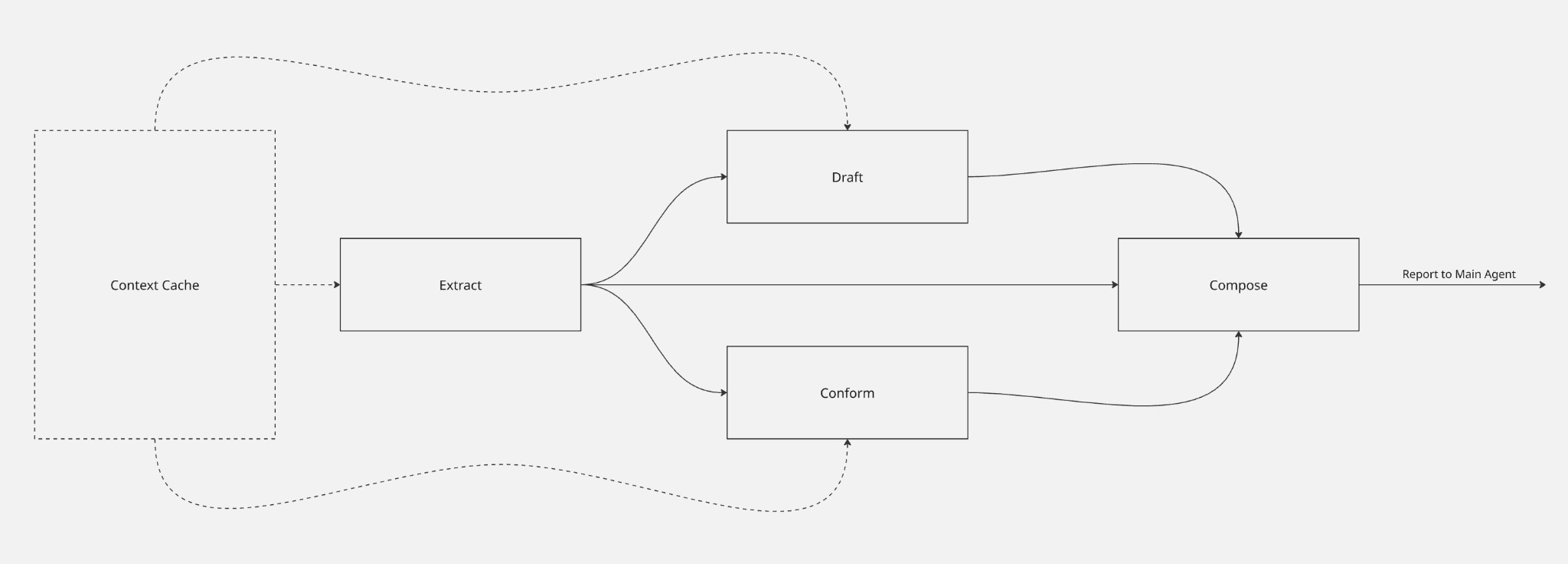
Extract -> Draft -> Conform -> Compose
Each of these passes followed a shared structure designed for reliability:
- Each phase is assigned a clearly defined persona - such as a Compliance Engineer - to steer the outcome toward a specific technical requirement.
- All phases interact with a local Context Cache containing both persistent CI documentation and dynamically fetched data relevant to the current operation.
- The workflow operates under a “Deterministic at Edges” philosophy, meaning every phase ingests and produces schema-enforced JSON strings alongside Markdown context.
- If a phase produces an invalid JSON string, a “helper phase” is called to fix the non-compliant segments, ensuring persistent communication between steps.
We go more in depth on the “Deterministic at Edges” design in Part 3.
Extract — gathering the repository’s raw data
In the Extract phase, the repository’s raw data is carefully analyzed to gather all necessary information. The main goal is to “clean up” the raw state of the repo by performing the exact “excavation work” - or tribal knowledge extraction - we cited earlier as the main timesink of complex brownfield migrations. This phase is a key contributor to the success of this new architecture.
It receives the largest “raw context”, provided as code and Markdown files, along with a rigorous set of instructions on what information it must extract from the repo’s files. This phase performs no judgment calls in the traditional sense; it doesn’t even decide if the repo’s contents are compatible with the process we’re employing (as can happen if some repos have highly customized the old CI flow). It simply “fills a form” with a list of information. Here’s a small snippet of the information collected by this phase, presented in the form of the JSON output it’s instructed to follow:
{
"arch": [],
"arch_note": "x86_64-only | arm64-only | multi-arch | unspecified",
"jenkins_logic": [{ "stage": "", "commands": [] }],
"makefile_targets": [],
"detected_artifacts": [],
"env_vars": [],
"helm_oci_enabled": false,
"docker_tag_strategy": "GITHUB_SHA | SEMVER | unknown",
"ecr_accounts": ["<AWS_ACCOUNT>"],
"runtime_tools": {
"detected": [],
"needs_mise": false,
"suggested_versions": {},
"mise_ci_exists": false,
"mise_exists": false,
"tool_versions_exists": false
}
}
Draft — a first, schema-compliant artifact
The Draft phase makes an early, initial attempt at creating the new platform’s “Main Artifact.” In our case, this is the artifact manifest for the repository. Our old CI platform had only an implicit artifact manifest document per repo - information that could be inferred from the Jenkinsfile if you understood the platform’s inner workings. In contrast, the new CI platform relies on a schema-enforced file in the repository to serve as the new platform’s source of truth. For this phase, the agent acts as a “Compliance Engineer.”
The Draft phase receives the JSON output produced by the Extract phase as input, along with a file from the Context Cache detailing the schema and guidelines for the expected output. The agent correlates the static data from the current repository state with the artifact documentation to construct the schema-enforced draft of the file. The output comprises both the drafted file - and textual notes this phase wants to pass the other ones
Conform — mapping the repo onto the new platform
While the Draft phase focuses on drafting the coded/schematic artifacts for the implementation step, the Conform phase determines what changes and modifications are necessary for that implementation due to the API change between the old and new platforms. For this phase, the agent acts as a “Senior CI Engineer” (to be modified according to your migration’s main role). This phase is crucial for performing a comprehensive mapping between the old and new platforms, detailing all necessary changes—from checking compatibility and adapting custom build scripts to determining required parameters and coordinating infrastructure changes in related repositories.
As the main role of this phase is to verify that the repo conforms to the new format and to detail any modifications needed, the prompt here would differ significantly between migration projects - unlike other phases, which retain the same general structure.
Compose — binding the analysis into a plan
The Compose phase, the fourth and final phase of this chain, is where it all comes together. The JSON outputs from the first three phases, alongside the repository’s Jenkinsfile (for reference), are passed to this phase. The agent is prompted to act as a “Senior Lead Engineer,” a seemingly general title meant to focus this phase on binding all the insights together into an executive summary. This allows the engineer overseeing the process to receive a general understanding of the effort required for this repo.
Here’s an example output of phase 4, summing up the key points:

This phase’s output consists of both the “implementation plan” as seen above and a full-length analysis summary Markdown file, both of which are passed back to the main agent thread. The agent first shows the user the compact implementation plan; if the user requests it, they can also receive the full plan to dive deep into any nuances or specific cases.
Attached here is a simplified visualisation of how the final analysis workflow operates.
Why the phases need each other
One interesting example that highlights the uniqueness of this structure revolved around the Draft phase’s output. This perfectly reflects the “agent specialists” philosophy we employ. Although the general CI workflow and parameters are handled in the Conform phase, the Conform phase’s recommendations are often insufficient for the full implementation because that agent would overlook information requiring knowledge of the artifact list. This signifies how this process - where each agent provides its own recommendations that are then bound together for the main agent - provides a much more complete picture of the repository’s state.
The Extract, Draft, Conform, and Compose phases, communicating via schema-enforced JSON, were critical for this success. However, this new-found speed and agility introduced a new, final challenge—a classic platform engineering dilemma: How do we balance Stability vs Agility? Continue the read into the third and final chapter in this series to read on our solution of it, and also to hear about the success we encountered here.


